mysql에 thread_cache_size라는 것이 있다.
이것의 역할은 connection당 스레드를 생성하고 해제할 때 메모리를 할당하고 캐시할 메모리(192K or 256K)를 미리 생성해놓고 적절하게 관리하는 용도이다.
일종의 connection pool기능을 하는 역할인데 현재 서비스 DB를 확인해보니 cache miss rate이 17% 정도된다.
mysql> show global variables like 'thread%';
+-------------------+---------------------------+
| Variable_name | Value |
+-------------------+---------------------------+
| thread_cache_size | 8 |
| thread_handling | one-thread-per-connection |
+-------------------+---------------------------+
mysql> show status like 'thread_%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 8 |
| Threads_connected | 106 |
| Threads_created | 62769 |
| Threads_running | 3 |
+-------------------+-------+
mysql> show status like 'connections%';
+---------------+--------+
| Variable_name | Value |
+---------------+--------+
| Connections | 357651 |
+---------------+--------+
1 row in set (0.00 sec)
//cache miss rate(%) = (Threads_created / connections) * 100 --> (62769/357651) * 100 = 17.5%스레드를 수정하는 것이라서 바로 반영하기엔 부담이 많이 되었고 miss rate 17%가 이게 좋은 것인지 나쁜것이지 판단이 안되었다.
여러가지로 자료조사를 해보니 국내 사이트에서는 튜닝한 사례를 소개한 글은 찾기 어려웠고..
시간이 좀 걸리긴 했지만 percona site와 High Performance MySQL 책에서 어느정도 답을 찾을 수 있었다.
1. 자료수집
1) percona site
https://www.percona.com/blog/2017/10/09/mysql-and-mariadb-default-configuration-differences/
여기에서 블로그 타고타고 들어갔던 거 같은데 현재는 못찾겠다.
일단 여기 엔지니어의 얘기로는 default =8 은 작고 적어도 default = 16이상 설정하는 게 좋다라고 되어있었다.
->따라서 1차적으로 thread_cache_size를 default에서 16으로 바꾸는 게 좋겠다고 판단했다.
2) High Performance MySQL 내용
#thread_cache_size
Setting this variable has no immediate effect—the effect is delayed until the next time a connection is closed.
At that time, MySQL checks whether there is space in the cache to store the thread.
If so, it caches the Thread for future reuse by another connection.
If not, it kills the Thread instead of caching it. In this case, the number of threads in the cache, and hence the amount of memory the thread cache uses, does not immediately decrease;
it decreases only when a new connection removes a thread from the cache to use it.
(MySQL adds threads to the cache only when connections close and removes them from the cache only when new connections are created.)
이 변수를 설정하는 것은 즉각적인 효과는 없다. 그 효과는 다음 번에 연결(connection)이 닫힐 때까지 지연된다.
이때 MySQL은 캐시에 스레드를 저장할 공간이 있는지 확인한다. 공간이 있다면 또 다른 연결(connection)에 의해 나중에 재사용할 수 있도록 스레드를 캐싱한다.
공간이 없다면 그것을 캐싱하는 대신 스레드를 죽인다. 이 경우 캐시에 있는 스레드 수와 그에 따른 사용 메모리양이 즉시 감소하지는 않는다.
새 연결이 캐시에서 스레드를 제거하여 사용할 때만 감소한다. (MySQL은 연결이 닫힐 때만 캐시에 스레드를 추가하고 새 연결이 생성될 때만 캐시에서 스레드를 제거함)
#thread_cache_size
You can compute a reasonable value for this variable by observing the server’s behavior over time.
Watch the Threads_connected status variable and find its typical maximum and minimum.
You might want to set the thread cache large enough to hold the difference between the peak and off-peak usage, and go ahead and be generous,
because if you set it a bit too high it’s not a big problem. You might set it two or three times as large as needed to hold the fluctuations in usage.
당신은 시간이 지남에 따라 서버의 동작을 관찰함으로써 이 변수에 대한 합리적인 값을 계산할 수 있다.
Threads_connected 상태 변수를 보고 일반적인 최대값과 최소값을 찾으십시오.
스레드 캐시를 최대 사용량과 최소 사용량 간의 차이를 충분히 수용할 수 있을 정도로 크게 설정하고, 계속하여 관대하게 처리하십시오.
왜냐하면 너무 높게 설정하는 것은 그리 큰 문제가 되지 않기 때문이다. 사용량의 변동을 억제하기 위해 필요한만큼의 두 세 배정도로 크게 설정할 수도 있다.
-> 이것에서 많은 힌트를 얻었다. 여기에서 설명하는 내용을 정리해보면 평소 connection의 수와 max connection의 수의 차만큼 thread_cache_size를 할당하는 것으로 확인하였다.
그리고 아래는 그것에 대한 예를 들고 있다.
For example, if the Threads_connected status variable seems to vary between 150 and 175, you could set the thread cache to 75.
But you probably shouldn’t set it very large, because it isn’t really useful to keep around a huge amount of spare threads waiting for connections;
a ceiling of 250 is a nice round number (or 256, if you prefer a power of two).
You can also watch the change over time in the Threads_created status variable.
If this value is large or increasing, it’s another clue that you might need to increase the thread_cache_size variable.
예를 들어, Threads_connected 상태 변수가 150과 175 사이에 차이가 나는 경우, 스레드 캐시를 75로 설정할 수 있다.
하지만 아마도 당신은 그것을 그리 크게 설정해서는 안 될 것이다. 엄청난 양의 여분의(spare) 스레드가 접속을 기다리게 하는 것은 별로 유용하지 않기 때문이다.
최대 한계값 250은 좋은 근사치값이다. (또는 만약 제곱을 원한다면 256)
Thread_created 상태 변수에서도 시간에 따른 변화를 볼 수 있다.
이 값이 크거나 증가하면 Thread_cache_size 변수를 늘려야 할 수도 있다는 또 다른 단서다.
Check Threads_cached to see how many threads are in the cache already.
A related status variable is Slow_launch_threads.
A large value for this status variable means that something is delaying new threads upon connection.
This is a clue that something is wrong with your server, but it doesn’t really indicate what.
캐시에 이미 있는 스레드 수를 보려면 Thread_cached 를 확인하세요.
관련 상태 변수는 Slow_launch_threads이다.
이 상태 변수의 큰 값은 연결 시 어떤 것이 새 스레드를 지연시키고 있음을 의미한다.
이것은 서버에 문제가 있다는 단서지만, 실제로 무엇을 나타내지는 않는다.
It usually means there’s a system overload, causing the operating system not to schedule any CPU time for newly created threads.
It doesn’t necessarily indicate that you need to increase the size of the thread cache.
You should diagnose the problem and fix it rather than masking it with a cache, because it might be affecting other things, too.
이는 대개 시스템 과부하가 발생하여 운영 체제가 새로 생성된 스레드의 CPU 시간을 스케줄(일정을 계획)하지 못하게 한다는 것을 의미한다.
반드시 스레드 캐시의 크기를 늘릴 필요가 있음을 나타내는 것은 아니다.
다른 것에도 영향을 줄 수 있기 때문에 캐시로 가리기보다는 문제를 진단하고 고쳐야 한다.
#The Thread Cache
The thread cache holds threads that aren’t currently associated with a connection but are ready to serve new connections.
When there’s a thread in the cache and a new connection is created, MySQL removes the thread from the cache and gives it to the new connection.
When the connection is closed, MySQL places the thread back into the cache, if there’s room.
If there isn’t room, MySQL destroys the thread. As long as MySQL has a free thread in the cache it can respond rapidly to connection requests, because it doesn’t have to create a new thread for each connection.
스레드 캐시는 현재 연결과 연결되지 않았지만 새 연결을 제공할 준비가 된 스레드를 보관한다.
캐시에 스레드가 있고 새 연결이 생성되면 MySQL은 캐시에서 스레드를 제거하여 새 연결에 부여한다.
연결이 닫히면 MySQL은 공간이 있는 경우 스레드를 캐시에 다시 넣는다. 공간이 없으면 MySQL은 스레드를 파괴한다.
MySQL이 캐시에 사용가능한(free) 스레드가 있는 한 각 연결에 대해 새 스레드를 만들 필요가 없기 때문에 연결 요청에 빠르게 응답할 수 있다.
The Thread_cache_size variable specifies the number of threads MySQL can keep in the cache.
You probably won’t need to configure this value unless your server gets many connection requests.
To check whether the thread cache is large enough, watch the Threads_created status variable.
thread_cache_size 변수는 MySQL이 캐시에 보관할 수 있는 스레드 수를 지정한다.
서버가 많은 연결 요청을 받지 않는 한 이 값을 구성할 필요가 없을 것이다.
스레드 캐시가 충분히 큰지 확인하려면 Threads_created 상태 변수를 확인하세요.
We generally try to keep the thread cache large enough that we see fewer than 10 new threads created each second, but it’s often pretty easy to get this number lower than 1 per second.
A good approach is to watch the Threads_connected variable and try to set Thread_cache_size large enough to handle the typical fluctuation in your workload.
For example, if Threads_connected usually stays between 100 and 120, you can set the cache size to 20.
If it stays between 500 and 700, a thread cache of 200 should be large enough.
우리는 일반적으로 초당 10개 미만의 새로운 스레드가 생성되는 것을 볼 수 있을 정도로 스레드 캐시를 크게 유지하려고 노력하지만, 종종 이 숫자를 초당 1보다 낮게 설정하는 것은 꽤 쉽다.
좋은 접근방식은 Threads_connected 변수를 관찰하고 일반적인 워크로드의 변동을 처리할 수 있을 만큼 thread_cache_size를 크게 설정하는 것이다.
예를 들어, 일반적으로 Threads_connected의 수가 100에서 120 사이인 경우 캐시 크기를 20으로 설정할 수 있다.
500에서 700사이에 머문다면 thread_cache_size는 200정도로 충분히 커야 한다.
Think of it this way: at 700 connections, there are probably no threads in the cache;
at 500 connections, there are 200 cached threads ready to be used if the load increases to 700 again.
Making the thread cache very large is probably not necessary for most uses, but keeping it small doesn’t save much memory, so there’s little benefit in doing so.
Each thread that’s in the thread cache or sleeping typically uses around 256 KB of memory.
이렇게 생각해 보십시오. 700개의 연결에서 캐시에 스레드가 없을 수 있으며,
500개의 연결에서, 부하가 다시 700개로 증가할 경우 사용할 수 있는 캐시된 스레드가 200개 있다.
스레드 캐시를 매우 크게 만드는 것은 아마도 대부분의 용도에 필요하지 않을 것이지만, 작게 유지하는 것은 많은 메모리를 절약하지 못하므로 그렇게 하는 것이 별로 이득이 되지 않는다.
스레드 캐시에 있거나 절전 모드인 각 스레드는 일반적으로 약 256KB의 메모리를 사용한다.
This is not very much compared to the amount of memory a thread can use when a connection is actively processing a query.
In general, you should keep your thread cache large enough that Threads_created doesn’t increase very often.
If this is a very large number, however (e.g., many thousand threads), you might want to set it lower because some operating systems don’t handle very large numbers of threads well, even when most of them are sleeping
이는 연결이 쿼리를 능동적으로 처리할 때 스레드가 사용할 수 있는 메모리 양에 비하면 그리 많지 않다.
일반적으로 스레드_생성된 스레드 캐시가 자주 증가하지 않을 정도로 충분히 큰 스레드 캐시를 유지해야 한다.
그러나 이 수가 매우 많은 경우(예: 수천 개의 스레드) 일부 운영 체제는 많은 수의 스레드를 잘 처리하지 못하기 때문에 대부분의 스레드가 절전 모드일 때 조차도 이 스레드를 낮게 설정하는 것이 좋다.
-> 예상치 못한 메모리 leak이 발생할 수도 있다고 한다. 반영후 2주정도 확인해서 적정값을 찾아야 한다. 1%내외로 유지하는 것이 목표
2. 서비스 DB 반영
1차 반영)
percona 엔지니어의 얘기대로 일단 defalut에서 16으로 변경하고 cache miss rate이 떨어지는지 확인함
SET global thread_cache_size = 16;
mysql> show global variables like 'thread%';
+-------------------+---------------------------+
| Variable_name | Value |
+-------------------+---------------------------+
| thread_cache_size | 16 |
| thread_handling | one-thread-per-connection |
+-------------------+---------------------------+
mysql> show status like 'connections';
+---------------+--------+
| Variable_name | Value |
+---------------+--------+
| Connections | 490123 |
+---------------+--------+
1 row in set (0.00 sec)
mysql> show status like 'thread_%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 4 |
| Threads_connected | 106 |
| Threads_created | 74044 |
| Threads_running | 3 |
+-------------------+-------+
4 rows in set (0.00 sec)
mysql> show status like '%thread%';
+------------------------------------------+-------+
| Variable_name | Value |
+------------------------------------------+-------+
| Delayed_insert_threads | 0 |
| Performance_schema_thread_classes_lost | 0 |
| Performance_schema_thread_instances_lost | 0 |
| Slow_launch_threads | 0 |
| Threads_cached | 0 |
| Threads_connected | 125 |
| Threads_created | 83512 |
| Threads_running | 5 |
+------------------------------------------+-------+
8 rows in set (0.00 sec)
//cache miss rate(%) = (Threads_created / connections) * 100 --> (74044/490123) * 100 = 15.10%
//-> cache miss rate이 떨어지는 것을 확인함
#주의점!
-> Slow_launch_threads 값을 반드시 확인해야함
# Slow_launch_threads
이 값이 크다면 어떠한 원인으로 새 스레드를 지연시키고 있음을 의미한다. 이것은 서버에 문제가 있다는 단서지만, 실제로 무엇인지 나타내지는 않는다.
이는 대게 시스템 과부하가 발생하여 운영체제가 새로 생성된 Thread의 CPU time을 스케줄(일정을 계획)하지 못하게 된다는 것이다.
반드시 스레드 캐시의 크기를 늘릴 필요가 있음을 나타내는 것은 아니다. 다른 것에도 영향을 줄 수 있기 때문에 캐시로 가리기보다는 문제를 진단하고 고쳐야 한다.
2차)
1주일정도 모니터링해보니 cache_miss rate 떨어지고 시스템에 영향이 없어 High Performance MySQL 내용대로 추가 반영를 계획함
peak time시 thread_connected를 확인하여 그 차만큼 thread_cache_size를 늘린다.
mysql> show status like 'thread_%'; 로 확인해보니 현재 DB의 connection thread는 110~150사이였다.
바로 48을 반영하고 싶었지만 절반인 24를 할당하여 한번 더 확인하기로 하였다.
SET global thread_cache_size = 24;
cache miss rate(%) = (Threads_created / connections) * 100 -> 3.7%
-> 3시간단위의 max와 표준편차를 이력추척해보았는데 3.7%정도 나온다.
조금 더 내려본다. 보통 max가 150정도 low가 110이라 40정도 생각한다.
이진법으로 확인해서 24의 두배인 48로 올려보고 다시 로그를 모니터링 해본다.
3차)
SET global thread_cache_size = 48;
-> High Performance MySQL저자 말대로 나도 이진법을 믿는 사람중에 하나일까?ㅎ
cache miss rate(%) = (Threads_created / connections) * 100 -> 0.35%
-> 이제 적정값을 찾았다. 모니터링하면서 miss rate가 감소하는지 확인한다.
3. 반영결과
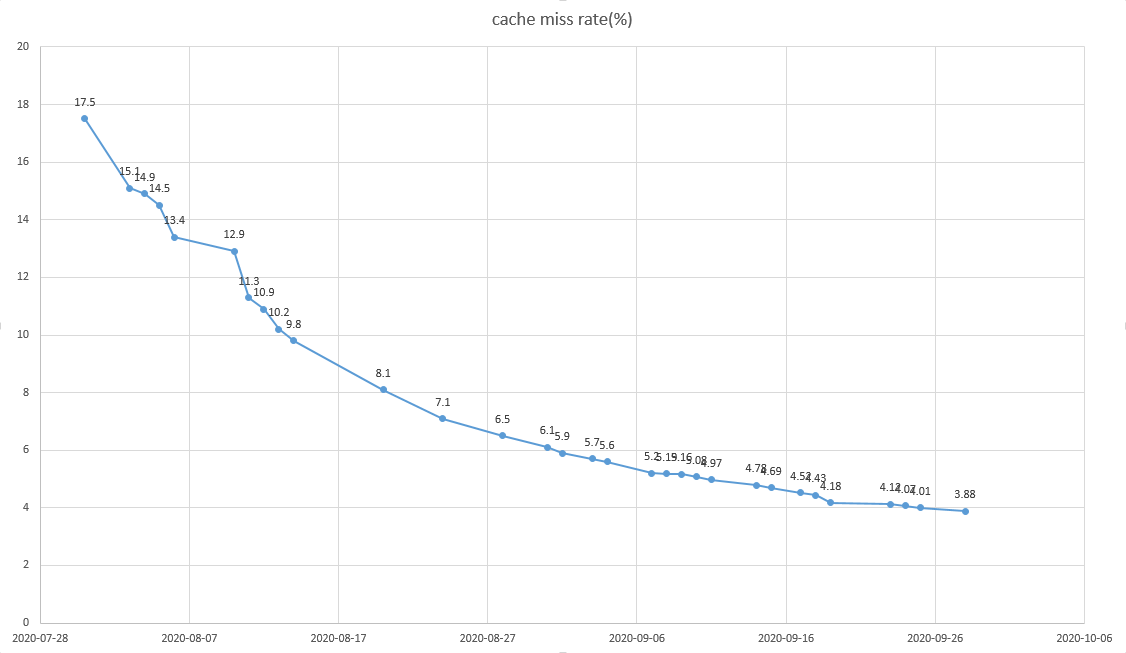
한달 안에 1%로 가는 것이라고 생각했지만, 중간에 1번의 장애라는 변수(Threads_created 값이 급증;)가 생겨서 실제 수지는 그렇게 바로 내려가지 않았다.
하지만 현재도 시간단위 추적해보면 1% 내외이고 적정한 튜닝으로 확인하였다. 언젠간 1%로 내려가겠지..
아래는 반영후 모니터링 값이다. 요즘 장애가 많이 줄었고, 여유로운 cpu usage를 볼때마다 뿌듯하다.
끝~
'RDB > mysql' 카테고리의 다른 글
| 점차 멀어지는 mysql vs MariaDB (0) | 2020.11.10 |
|---|---|
| mysql text 형 어떤 걸 쓸까? (0) | 2020.10.15 |
| [튜닝] 유물발굴 (mysql tuning using heavy query) (0) | 2020.09.18 |
| mysql을 시작하기 전에 3 (8) | 2020.08.26 |
| mysql을 시작하기 전에 2 (0) | 2020.08.11 |

dung beetle
취미는 데이터 수집 직업은 MYSQL과 함께 일하는 DBA의 소소한 일상 이야기